Learning Sphinx
Matthew Louis / August 2024 (1548 Words, 9 Minutes)
Note
If you’d like to see how I implemented any of the features described in this blogpost into the documentation for one of my own projects, take a look at my Sphinx setup here or my generated documentation here
Introduction
For a recent project, I wanted to try my hand at generating documentation. From other projects, I’d heard of tools like Doxygen, but after some brief research, I found that Sphinx was more commonly used for documenting python projects (although it’s completely generic and works for compiled languages like C++ just as well). And so I began my journey. The most helpful resource (oddly enough) was the actual Sphinx documentation (which is also written using Sphinx, it seems) and that helped me get up-and-running.
Choosing a Theme
Not to quote their documentation, but Sphinx has wide range of a bulit-in and third party themes that make styling your documentation about as easy as it is with Jekyll. Given that most of my summer internship was working with the SCALE code system, I began to fancy their documentation, and ultimately chose the same Read the Docs theme. My only qualms were that the default width was a little too small (this is intentional: to provide a decent experience to mobile users, but I decided that wasn’t a priority) so I ended up following this Stack Overflow post to increase the width (just like in the SCALE manual) which amounted to this css style to the documentation’s custom css (_static/css/custom.css)
/* Modify the content width of the sphinx readthedocs theme */
.wy-nav-content {
max-width: 1200px !important;
}Sphinx Autodoc
Once I’d chosen a theme, it was off to generating the documentation. I’d already written a decent amount of my functions/classes with docstrings just for maintainability, and it turns out that’s all you need to generate API documentation with Sphinx autodoc. This sphinx extension automatically generates the correct .rst files (which sphinx then uses to generate the resulting documentation, a .html site in my case) for documenting every function, class, module, and subpackage in your code, provided your docstrings are formatted correctly. Unfortunately I’d been using some (unbeknownst to be) modified version of the NumPy docstring format so I had to rewrite all of them anyways. Note that, by default, the autodoc extension only supports .rst formatted docstrings, and you havew to include the napoleon extension to get support for NumPy (and Google) style docstrings.
Adding Typehints
Another thing to help generate your documentation more easily is to use typehints in your function/class declarations along with the typehints Sphinx extension to automatically generate documentation with correct type annotations (and default values, etc.). This can be more convenient and scalable than manually specifying types in the docstring, and if you’re abiding by PEP, it’s actually recommended in PEP 0484 so you’re killing two birds with one software tool, so to speak. With autodoc and typehints, a docstring like this
def cache_all_libraries(base_library: Path, perturbation_factors: Path, reset_cache: bool=False,
num_cores: int=multiprocessing.cpu_count()//2) -> None:
"""Caches the base and perturbed cross section libraries for a given base library and perturbed library paths.
Parameters
----------
base_library
Path to the base cross section library.
perturbation_factors
Path to the cross section perturbation factors (used to generate the perturbed libraries).
reset_cache
Whether to reset the cache or not (default is ``False``).
num_cores
The number of cores to use for caching the perturbed libraries in parallel (default is half the number of cores
available).
Returns
-------
This function does not return a value and has no return type.
Notes
-----
* This function will cache the base cross section library and the perturbed cross section libraries in the user's home
directory under the ``.tsunami_ip_utils_cache`` directory. If the user wishes to reset the cache, they can do so by
setting the ``reset_cache`` parameter to ``True`` in the :func:`cache_all_libraries` function.
* The caches can be `very` large, so make sure that sufficient space is available. For example, caching SCALE's 252-group
ENDF-v7.1 library and all of the perturbed libraries currently available in SCALE (1000 samples) requires 48 GB of space,
and for ENDF-v8.0, it requires 76 GB of space.
* The time taken to cache the libraries can be significant (~5 hours on 6 cores, but this is hardware dependent), but when
caching the libraries a progress bar will be displayed with a time estimate.
* Note, if using ``num_cores`` greater than half the number of cores available on your system, you may experience excessive
memory usage, so proceed with caution.
"""and the resulting documentation looks like this:

Adding Support for LaTex in Docstrings
As a nuclear engineer, I mainly do scientific computing work, so it’s handy to be able to render LaTex in docstrings. With Sphinx, all you need to do is include Sphinx MathJax, which allows you to write inline math or full-on multiline equations.
Support For Doctests
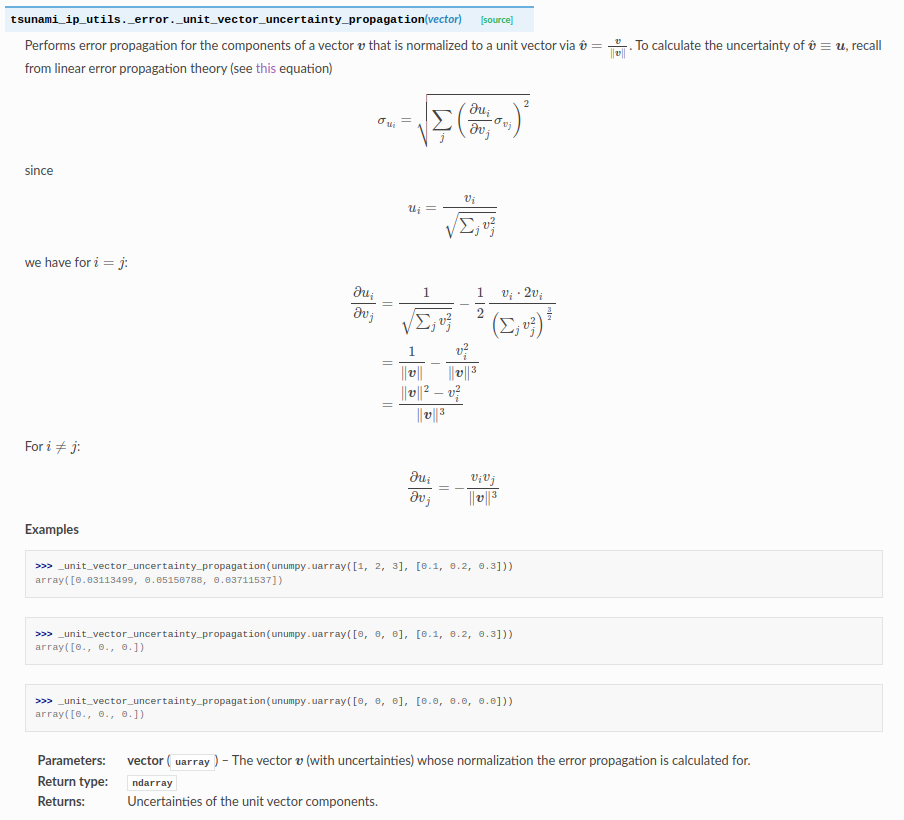
Another nice feature is full support for doctests. These are small tests that are literally included in the docstring of the function they test and consists of a series of inputs and outputs that a user might get from running a python shell session. Their purpose is twofold: it provides examples which help document the function, and it serves as a test case. Again, all you have to do is include the Sphinx Doctest extension. To show just how powerful this is, here’s an example function signature (with docstring)
def _unit_vector_uncertainty_propagation(vector: unumpy.uarray) -> np.ndarray:
"""Performs error propagation for the components of a vector :math:`\\boldsymbol{v}` that is normalized to a unit vector
via :math:`\\hat{\\boldsymbol{v}} = \\frac{\\boldsymbol{v}}{\\lVert\\boldsymbol{v}\\rVert}`. To calculate the uncertainty
of :math:`\\hat{\\boldsymbol{v}}\\equiv \\boldsymbol{u}`, recall from linear error propagation theory
(see `this <https://en.wikipedia.org/wiki/Propagation_of_uncertainty#Simplification>`_ equation)
.. math::
\\sigma_{u_i} = \\sqrt{ \\sum_j \\left( \\frac{\\partial u_i}{\\partial v_j} \\sigma_{v_j} \\right)^2 }
since
.. math::
u_i = \\frac{v_i}{\\sqrt{\\sum_j v_j^2}}
we have for :math:`i=j`:
.. math::
\\frac{\\partial u_i}{\\partial v_j} &=
\\frac{1}{\\sqrt{\\sum_j v_j^2}} - \\frac{1}{2}\\frac{v_i\\cdot 2v_i}{\\left(\\sum_j v_j^2\\right)^{\\frac{3}{2}}}\\\\
&=\\frac{1}{\\lVert \\boldsymbol{v}\\rVert} - \\frac{v_i^2}{\\lVert \\boldsymbol{v}\\rVert^3}\\\\
&=\\frac{\\lVert \\boldsymbol{v}\\rVert^2 - v_i^2}{\\lVert \\boldsymbol{v}\\rVert^3}
For :math:`i\\neq j`:
.. math::
\\frac{\\partial u_i}{\\partial v_j} = -\\frac{v_iv_j}{\\lVert\\boldsymbol{v}\\rVert^3}
Examples
--------
>>> _unit_vector_uncertainty_propagation(unumpy.uarray([1, 2, 3], [0.1, 0.2, 0.3]))
array([0.03113499, 0.05150788, 0.03711537])
>>> _unit_vector_uncertainty_propagation(unumpy.uarray([0, 0, 0], [0.1, 0.2, 0.3]))
array([0., 0., 0.])
>>> _unit_vector_uncertainty_propagation(unumpy.uarray([0, 0, 0], [0.0, 0.0, 0.0]))
array([0., 0., 0.])
Parameters
----------
vector
The vector :math:`\\boldsymbol{v}` (with uncertainties) whose normalization the error propagation is
calculated for.
Returns
-------
Uncertainties of the unit vector components."""and here’s what the generated .html documentation looks like
Intersphinx and Source Code
If you’re a freak about hyperlinks (like I am), you’ll be happy to know that in examples or documentation, you can automatically hyperlink all functions/modules/classes to their corresponding documentation using intersphinx. You can use it to link to external projects, or your own (so long as it’s published online). This feature is truly amazing, and one of the things that really sends Sphinx over the top for me, especially since most python packages have intersphinx compatible documentation. Another nice feature is the ability to include source code within your documentation (for the more hardcore documentation browsers) via the viewcode extension.
Sphinx Gallery
I think the most powerful Sphinx extension (at least for the type of projects I develop) is Sphinx Gallery. This is an extension that automatically creates documentation for examples (especially those that produce graphical output) by simply running a python script and capturing the output. So, you can use the examples you probably have already written for users, throw on some formatting, and you get gorgeous documentation. Not only does this work for static image output, but it also works for interactive plot frameworks like Plotly, and will capture a Plotly plot and embed it as fully-interactive html in the documentation. Again, if you have intersphinx, all of the relevant functions/classes/modules included in your examples will automatically be linked to their corresponding documentation. And if you have something more complicated, you can write your own scrapers for arbitrary content (so long as it can be embedded in an html webpage) - over the summer I developed a custom scraper that embeds a custom interactive matrix plot on the webpage within an Iframe that allows zooming in and out (see an example here). For anyone developing a visualization tool, or any project that encorporates scientific data visualization in any way, this extension is a must have.
Conclusions
I’m happy to have learned Sphinx, and kind of upset I didn’t pick it up sooner. Although it’s only really necessary for larger projects, it’s still good to know what can be done so you can appropriately structure your project and docstrings so that adding in Sphinx later on is seamless. I honestly think Python might be the ideal usecase for Sphinx, so I’d like to try using it with C++ to see if it’s just as easy. And, just to explore a bitl, I’d also like to try my hand at Doxygen before I use Sphinx exclusively.
Comments
If you're logged in, you may write a comment here. (markdown formatting is supported)
No comments yet.